Java分布式:分布式事务
分布式事务
分布式事务就是指事务的参与者、支持事务的服务器、资源服务器以及事务管理器分别位于不同的分布式系统的不同节点之上。简单的说,就是一次大的操作由不同的小操作组成,这些小的操作分布在不同的服务器上,且属于不同的应用,分布式事务需要保证这些小操作要么全部成功,要么全部失败。本质上来说,分布式事务就是为了保证不同数据库的数据一致性。
二阶段提交协议
两阶段提交其实比较简单,这边有两个资源提供准备和提交两个接口。
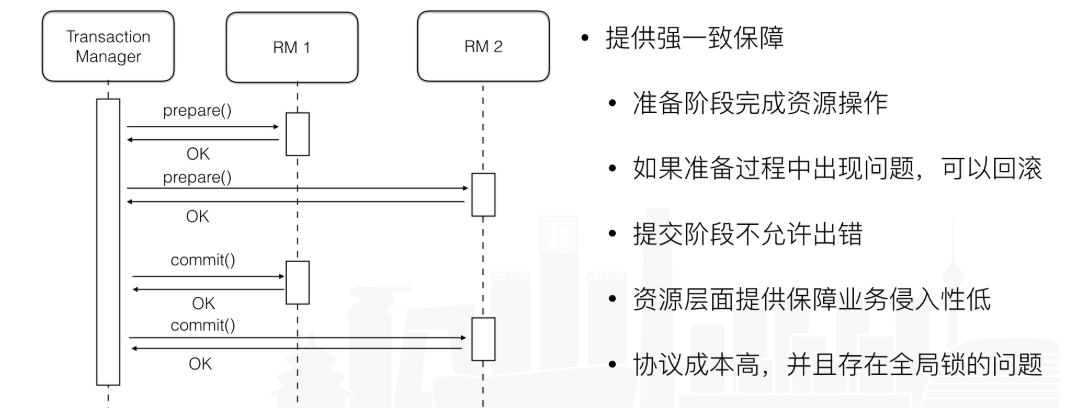
由于隔离性互斥的要求,在事务执行过程中,所有的资源都是被锁定的,这种情况只适合执行时间确定的短事务。 但是为了保证分布式事务的一致性,大都是采用串行化的隔离级别来保证事务一致性,这样会降低系统的吞吐。
但因为2PC的协议成本比较高,又有全局锁的问题,性能会比较差。 现在大家基本上不会采用这种强一致解决方案。
TCC协议
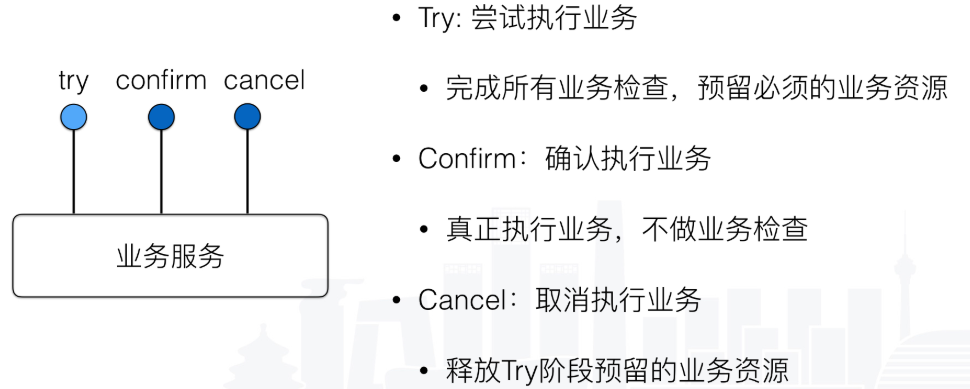
TCC名字的由来是其中包含了 try, confirm, cancel三个操作。
在一个跨服务的业务操作中,首先通过Try锁住服务中的业务资源进行资源预留,只有资源预留成功了,后续的操作才能进行。Confrim操作是在Try之后进行,对Try阶段锁定的资源进行业务操作。Cancel则是在所有操作失败时的回滚操作。TCC的操作都需要业务方 提供对应的功能,在开发成本上比较高。
与两阶段提交相比,TCC位于业务服务层, 没有单独的准备阶段,Try操作可以灵活选择业务资源锁的粒度。TCC是通过最终一致性来解决系统性能问题的这个设计,对我们设计抉择有很大的启发。 有些时候系统的技术问题是可以通过业务建模的方式来解决的。
Saga
Saga是30年前的一篇数据库论文里提到的一个概念。在论文中一个Saga事务就是一个长期运行的事务,这个事务是由多个本地事务所组成, 每个本地事务有相应的执行模块和补偿模块,当saga事务中的任意一个本地事务出错了, 可以通过调用相关事务对应的补偿方法恢复,达到事务的最终一致性。
Saga的两种执行顺序及恢复策略
横线上下分别为两张执行顺序:
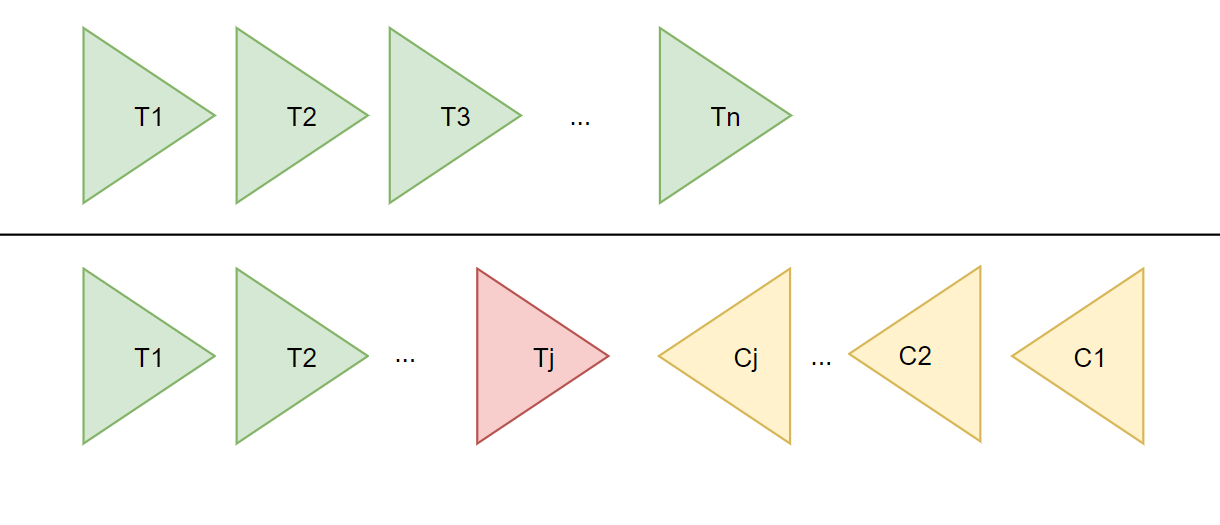
向前恢复,适用于必须要成功的场景,执行顺序类似于这样的:T1, T2, ..., Tj(失败), Tj(重试),..., Tn,其中j是发生错误的sub-transaction。该情况下不需要Ci。
向后恢复,即上面提到的第二种执行顺序,其中j是发生错误的sub-transaction,这种做法的效果是撤销掉之前所有成功的sub-transation,使得整个Saga的执行结果撤销。
参考链接